.png)
When was the last time you found yourself retyping text from a document or an image just because you couldn’t copy it directly? Chances are, it was frustrating and time consuming. This is exactly where Optical Character Recognition (OCR) steps in. OCR has quickly become one of the most practical technologies in our everyday workflow, helping businesses and individuals convert printed or handwritten text into machine readable data.
In this post, I’ll walk you through what OCR is, why it matters, and share a glimpse of the work I recently did around OCR including extracting text, measuring confidence levels, and structuring the results in a way that’s actually usable.
What is OCR and Why Does It Matter?
.png)
OCR, or Optical Character Recognition, is the process of identifying and extracting text from images, scanned documents, or even photos captured on your phone. Instead of manually typing out long passages, OCR technology automates this task by saving time, reducing errors, and making information searchable.
From digitizing old books and receipts to streamlining data entry in industries like healthcare, banking, and logistics, OCR has countless real world applications. In short: it’s not just about reading text, it’s about unlocking information that was previously “stuck” in images.
My Recent Work with OCR

Recently, I worked on a project where OCR was at the core. The goal was simple: take scanned images, extract the text, and also provide additional context such as how confident the system was about the recognition accuracy.
Here’s what the workflow looked like:
- Scanned Images: We started with a batch of images captured directly within the app.
- OCR Extraction: Using two different engines namely Scanbot OCR and Apple’s native Vision OCR we recognized the text.
- Confidence Scoring: Each recognized word came with a confidence value, allowing us to calculate an overall accuracy percentage for the extracted text. This helped us assess whether the OCR result was reliable enough.
- JSON Output: To make the results easy to process and integrate, we parsed the OCR data into structured JSON.
One of the most interesting parts of this project was comparing the OCR outputs between Scanbot and Apple’s Vision. It gave us a clear picture of where each engine performs better, and how confidence scores can guide decisions when text quality isn’t perfect.
Why Confidence Levels Matter
You might wonder: why bother with confidence percentages? Imagine scanning a contract where numbers or names need to be exact. A confidence score tells you how reliable the OCR result is and if the system is only 60% confident, it’s probably worth double checking.
In our project, confidence values ranged from 70% to 95%. By surfacing this number to users, we made the process more transparent and trustworthy. Instead of blindly accepting the OCR result, users know whether they can rely on it or if they need a second look.
Key Benefits of OCR in Practice
- Time Saving: Automates text extraction that would otherwise take hours.
- Accuracy with Transparency: Confidence scores give users more control.
- Structured Outputs: Exporting results in JSON makes them reusable in other systems.
- Versatility: Works across different OCR engines, so businesses can compare and choose what fits best.
Case Study: Uber’s Invoice Automation
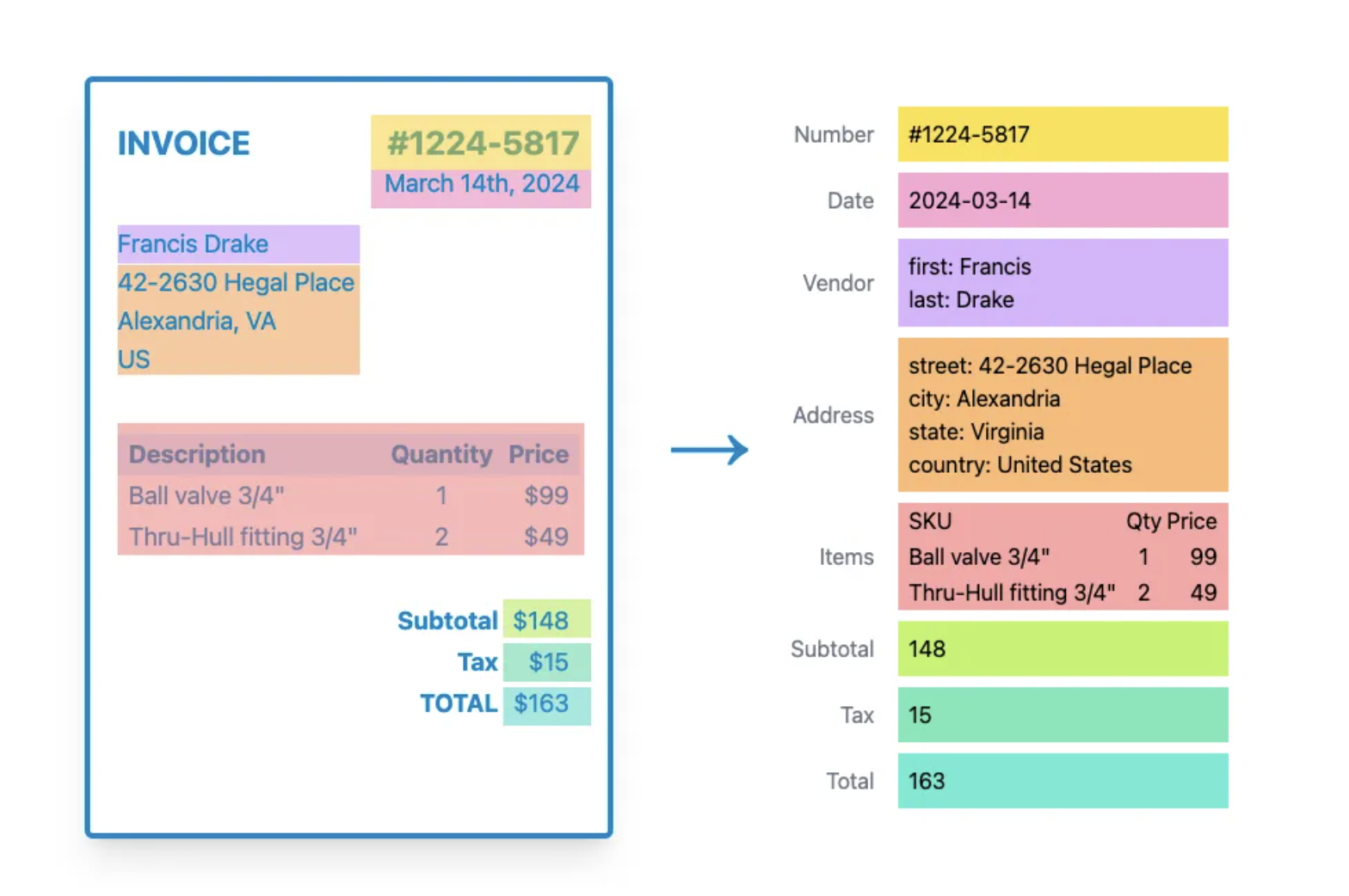
One of the best real world examples comes from Uber. The company processes thousands of invoices globally every month, and doing this manually required massive time and effort. Uber adopted a GenAI powered solution that combines OCR with natural language processing (NLP) to extract vendor names, amounts, dates, and other key details automatically.
This automation has helped Uber save millions of dollars, cut down on manual labor, and improve accuracy across its financial systems. It’s a powerful demonstration of how OCR can scale in enterprise environments and drive real business value.
The Future of OCR
OCR is no longer just about text recognition now it’s becoming a key building block in intelligent automation. Integrated with AI, OCR can understand document layouts, classify files, and even make decisions based on extracted data. This opens doors to fully automated workflows across industries.
Closing Thoughts
OCR is not anymore a “nice-to-have” tool, it’s becoming a necessity in any workflow that deals with documents, images, or data extraction. My recent work with OCR showed me just how powerful the technology can be when combined with user friendly outputs like confidence scoring and JSON parsing.
Whether you’re digitizing old archives, scanning receipts, or building smarter apps, OCR is transforming the way we read and process information. And with every project, it’s getting faster, more accurate, and easier to use.